The year is 2023. ChatGPT is all the rage. It is wonderfully exciting. It marks a shift in culture, and the beginning of a new era in human-AI/machine symbiosis. It posits large language models (LLMs) as useful tetchnology with ample more room to grow. It sure makes mistakes. And, if you are anything like me, you want to attempt a fix. You can’t really peek behind the scenes, but we are in luck. There are a couple12 of projects ongoing that aim to bring the tech, or equivalent thereof, behind ChatGPT, into the open. I encourage us all to join such projects.
This post is not about that tech, nor is it about ChatGPT. But it is about attempting a fix, albeit with humble beginnings. Yet, the goal is audacious, powered by a flame to engineer AI systems that humans can rely on, much like engineering a bridge. In this instance, a bridge that lets the human get from a query to a useful and reality grounded response.
Cohere’s sandbox
About a month ago, Cohere, the company brining LLM capabilities into the hands of developers across the planet, released their sandbox3. Cohere already has a playground4 (much like OpenAI’s) that I was drawn to for reasons outside the scope of this post, but in acute alignment with the tastes of my kids, I felt the pull of the sandbox. This is a set of open source applications built on top of the LLM endpoints that Cohere offers. Amongst these is the grounded Q&A5 bot, which showcases the idea of augmenting LLM capabilities with Google search results6.
LLMs have fantastic abilities to generate content derived from the data they have been trained on (and adapted to via finetuning or prompting, or other more complex model editing mechanisms), but the real world sits on firm ground with a life of its own that is also in flux. Search results based on consensus are one alternative to exposing reality to LLMs. It should be noted that they too have limitations. One limitaiton is that consensus mechanisms drive the relevancy of results relative to a search term, which may itself not be grounded in truth. Nick Frosst of Cohere explains the problem here. I set out to attempt a fix.
Brua the Critical
Given a question posed by a user, what if we have a way of checking if the question itself is grounded in reality? Enter Brua the Critical, a bot with an early instance of this capability – a question-grounding mechanism – expanding the capabilities of the grounded Q&A bot from Cohere’s sandbox. When it comes to Q&A, a fully reliable AI system would have many more capabilities than this. My aim with Brua is to expand the scope of its capabilities one humble step at a time, with feedback from you the reader. The eventual audacious goal is to make Brua the most reliable and safe to use Q&A system out there, whether limited to a narrow domain in the real world, or for answering open ended question.
This particular incarnation of Brua does not take any question for granted! Here is an early preview of how Brua responds to user questions, in cases where they seem to have factual issues. I welcome feedback on other ways Brua could respond to questions not grounded in reality. Also, in what ways we humans would challenge/question a question, e.g. from a linguistic or common sense perspective? All feedback on this will help make Brua more reliable.
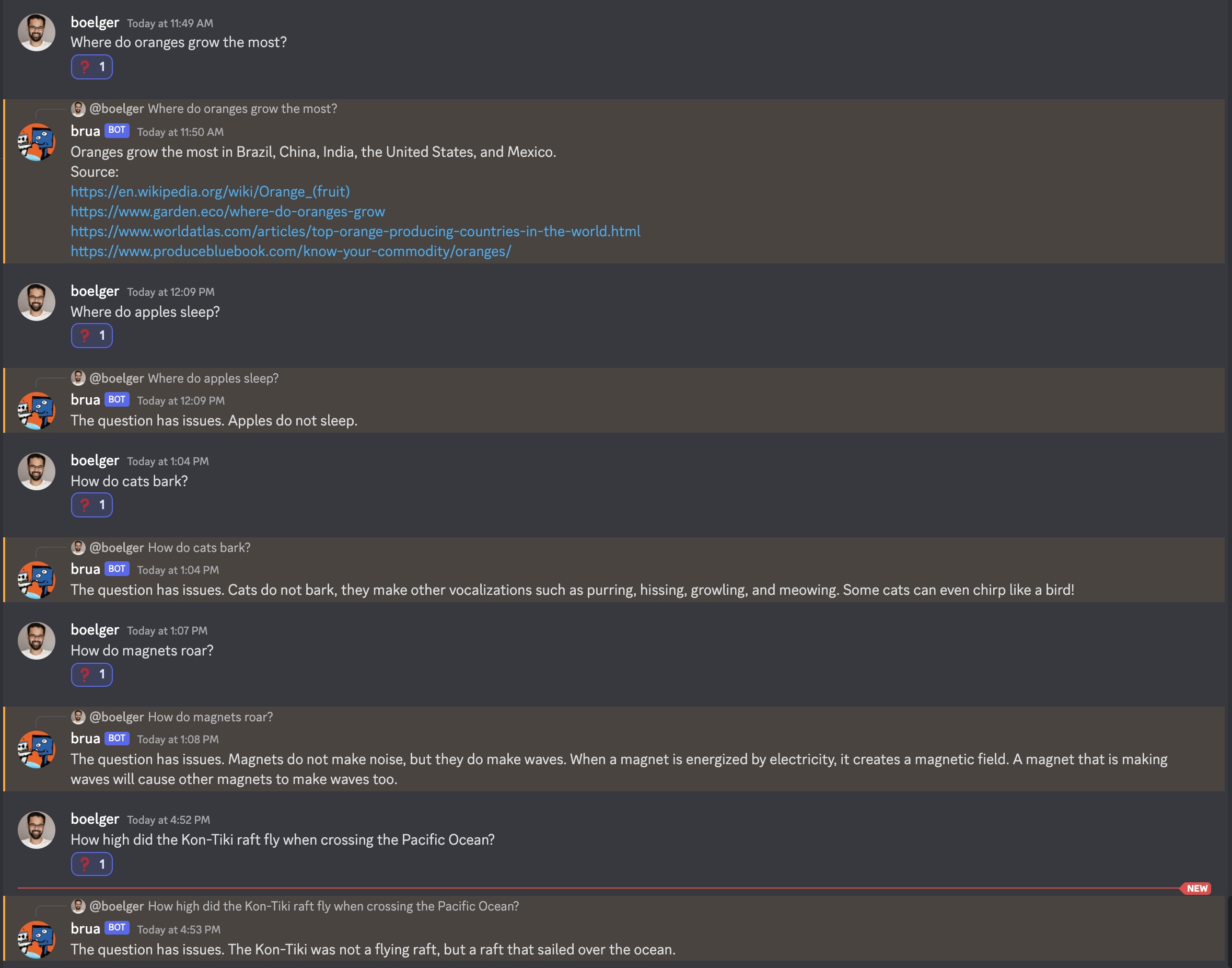
Brua as a discord bot attempting to answer questions having factual issues.
Getting more reliable with compute, and next steps
One of the key ideas in the design of Brua is the nature of its computational workload. The question-grounding mechanism, whilst increasing the inference time compute requirements, is designed to be embarrasingly parallel, thus Brua will get safer and more reliable with compute, with marginal, if any, effect on response times. This is one dimension along which I am extending Brua as we speak.
Another way I’ll be extending Brua is to use a reward model to further tailor the eventual response from the bot to be more human friendly/preferred in a linguistic sense. The way this latter feature could work in its rudimentary form is by having the LLM component that faces the user generate multiple responses, which would be ranked and filtered by reward (assuming monotonicity), favouring one with the highest.
So there we have it. Brua the Critical is looking for improvements and new capabilities, to eventually be known as Brua the Reliable!

The face of Brua on Discord, generated using Stable Diffusion v2.1 at DreamStudio using the prompt “A friendly robot and a human shaking hands, in the style of picasso and dali”.
Let’s chat?
By now you have noticed that I’ve left out the gory details of the question-grounding mechanism that Brua uses from this post. The mechanism is in flux, and at this stage, I’d love to talk more about Brua over a human-human chat with you. Why don’t you ping me @boelger. Perhaps we could also have a play with Brua, live!
Acknowledgements
It is an exciting time to witness and, behold, play at ease with the progress ongoing in the LLM capabilitiy space. I very much appreciate the existence of companies like Cohere to have made working with LLM capabilities as accessible to me, as is building and exploring new shapes in our sandbox for my kids (it is more like a snow covered box at present – i’ts January, and we are in Norway, but you get the idea). Thanks for inspiring this work on making LLM capabilities ever more reliable. I’d very much recommend people interested in LLM capability exploration to engage with the friendly Cohere and Cohere for AI communities.
Thanks also to my good friend Gordon Klaus for suggesting some edits to this post.
-
Retreival augmented language models is an active area of research. ↩